Note
The aim of this document is to expose the heuristics by which we consider what the appropriate process is for various types of service updates. We also describe our extant processes around Science Platform and Science Platform adjacent services, as these are likely to be of most interest to developers outside our team.
Note
This is a descriptive (not prescriptive) document describing details of current practice of a specific team in a specific area. For the actual developer guide, see developer.lsst.io
1 Background¶
SQuaRE uses Configuration as Code (aka “gitops”) practices for service deployment whenever practical. What this means is that by merging code or configuration to a special branch (typically master), it is possible to trigger an action (via an agent or supervisory system) that automatically results in the deployment of the new version of the service.
Whether the new version of the service is actually deployed automatically (a practice known as continuous deployment) or whose deployment is gated behind a human decision making process is a matter of policy. The barrier to getting through that gate is itself a function of where a system lies on an axis of formality, with one end maximizing developer agency and the other maximizing organisational control.
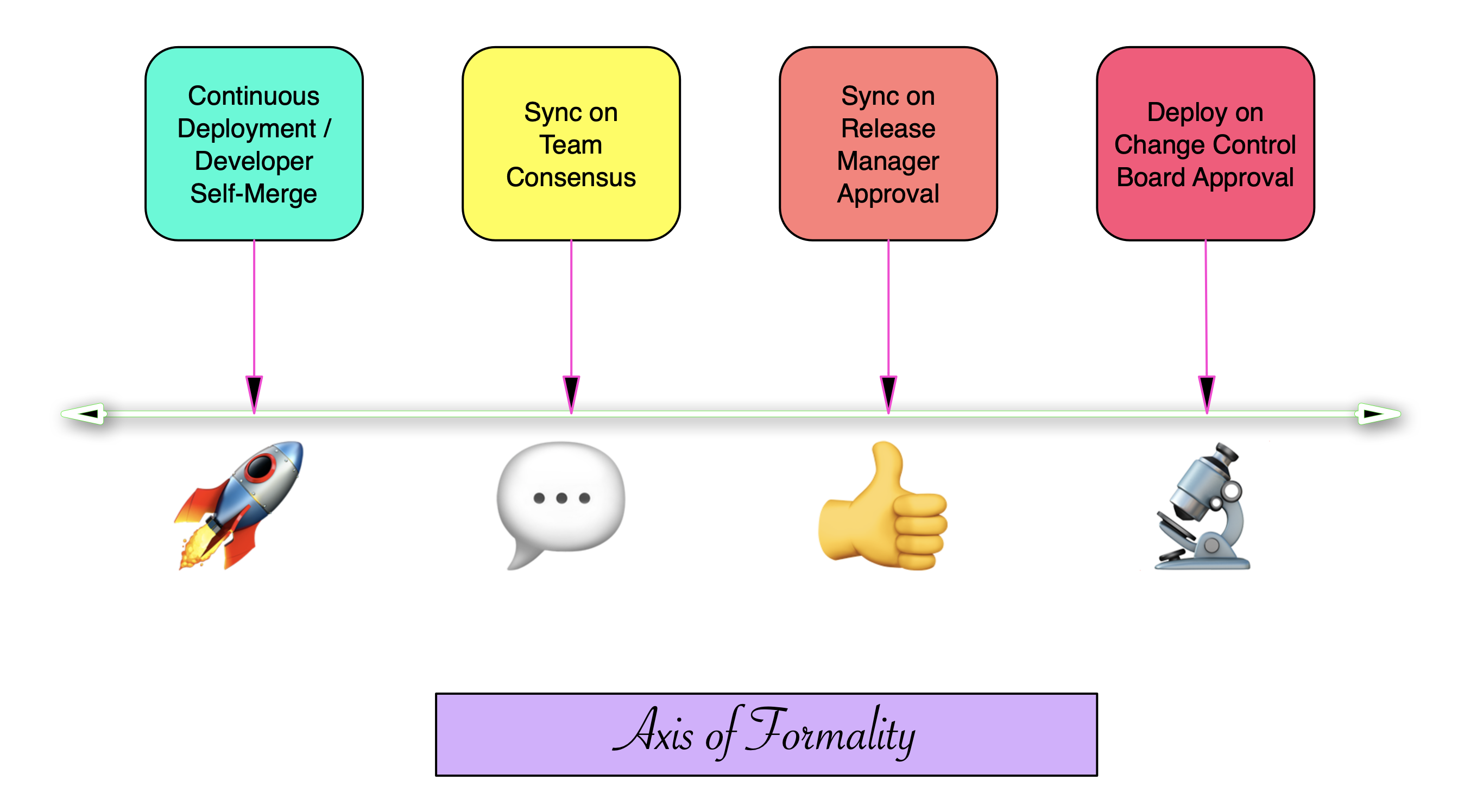
Figure 1 Some common examples along the axis of formality
Where any one particular instance of any one particular service lies in the Axis of Formality is a function of:
- The service’s maturity, including the number of users depending on the service
- The service environment, including whether it’s production, staging or development environment
- The service’s userbase, including whether it is a feature-seeking or risk averse population
- The actual and reputational impact of disruptions to the service
- The nature of the change being made.
It’s easy to see that a major change in a mature high visibility service that many users depend on is on the opposite side of the axis that a cosmetic change in a service under development deployed on a sandbox. The trickier situations lie in between these extremes, and the aim of this document is to expose the heuristics by which we consider these questions. We also describe our extant processes around the update of Science Platform and Science Platform adjacent services, as these are likely to be of most interest to developers outside our team and since they exercise a lot of the decision space described above.
2 Kubernetes services and Argo CD¶
SQuaRE develops Kubernetes-based services, and uses the ArgoCD platform to manage their deployment. The ArgoCD UI provides a valuable way both to assess the state of deployed services and to allow basic maintenance operations on deployed services even without being particularly intimate with the details of their deployments, and irrespective whether the underlying service is configured with Helm or kustomize.
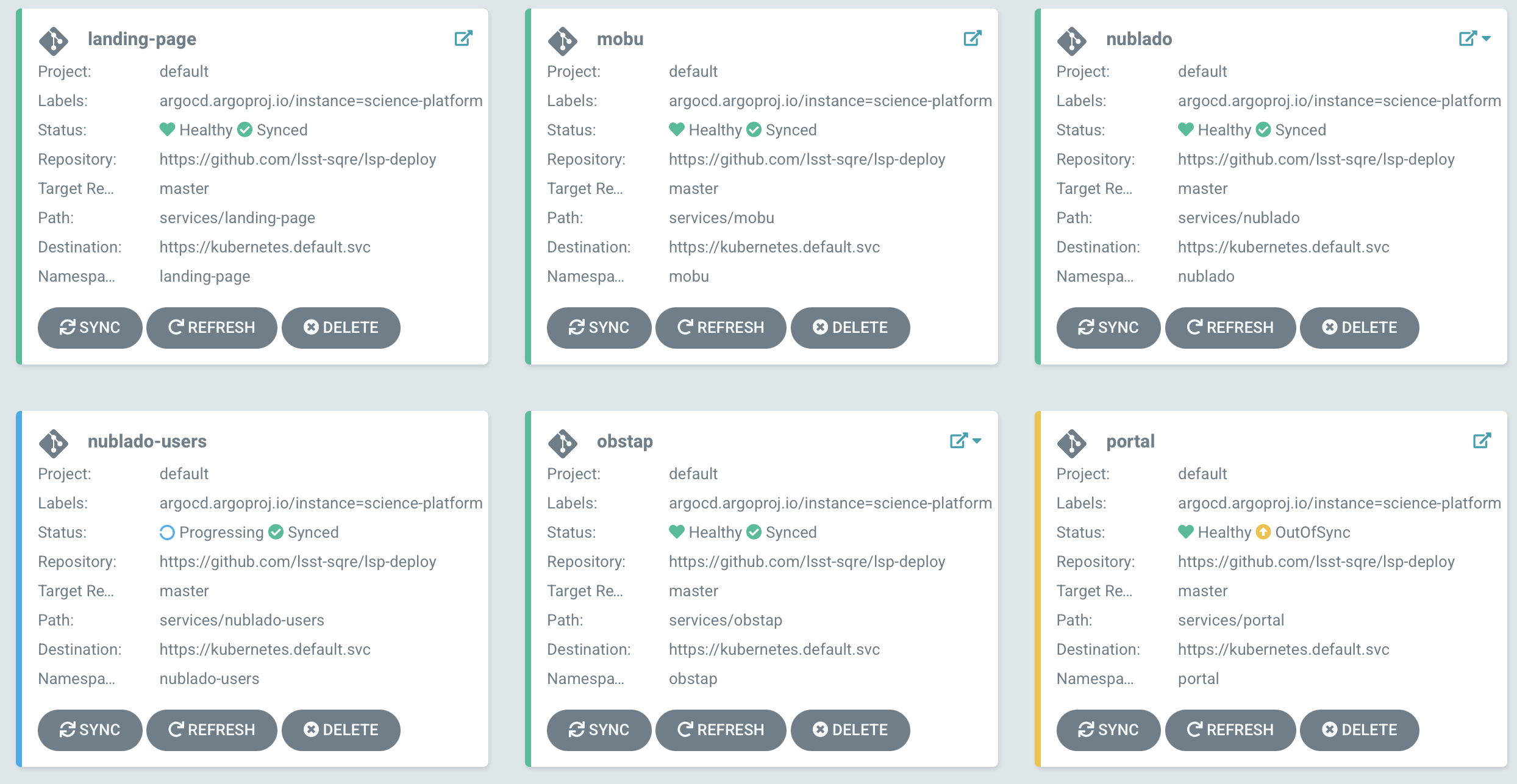
Figure 2 The overview panel of the ArgoCD UI
ArgoCD continuously monitors running services and compares their state with that of their git repo. When it detects that a service is “out of sync” (ie there is drift between its deployed state and the repository state) it can sync automatically (the continuous deployment model) or as in Figure 2, indicate visually the out-of-sync state until an engineer pushes the sync button to resolve it (the gated deployment model). Generally unless working in a dev or bleed environment, we do not allow ArgoCD to sync automatically.
It follows then that for gated deployments there are two aspects to getting a new version of a service deployed into production:
- Mechanics: Getting the right version of the service and its configuration merged into the deployment branch (typically master);
- Process: Going through the process that allows it to be synced into production.
3 Mechanics¶
Assume that there is a new release of Gafaelfawr, the authentication service used by the Rubin Science Platform. The following steps notify Argo CD that this upgrade is ready to be performed:
- Update the Helm chart in the [charts](https://github.com/lsst-sqre/charts) repository under charts/gafaelfawr. Do this by updating the appVersion key in Chart.yaml and the image.tag key in values.yaml to point to the new release. Also update the version of the Helm chart in Chart.yaml. When this PR is merged, a new version of the chart will be automatically published via GitHub Actions.
- Update the Argo CD configuration to deploy the new version of the chart. The Chart.yaml file in services/gafaelfawr in the [phalanx](https://github.com/lsst-sqre/phalanx) repository determines what version of the Gafaelfawr chart is installed by Argo CD. (Phalanx is the Argo CD configuration repository for the Rubin Science Platform.) Under the stanza for the gafaelfawr chart in the dependencies key, change the version to match the newly-released chart version. Once this PR is merged, Argo CD will notice there is a pending upgrade for Gafaelfawr.
4 Process¶
The process used to deploy a specific instance of a service depends on where it lies on the axis of formality above. We use the following terminology for the various deployment environments, in decreasing formality:
- Prod: Production, the user-facing deployment. For historical reasons sometimes referred to as “stable” where the Science Platform is concerned.
- Int: Integration, a deployment for developers, typically from different teams, to converge upon to test the integration of services prior to deployment on Prod. This is the environment somethings referred to as “staging”. For telescope deployments, this is currently the NCSA Test Stand [NTS]
- Dev: Development, an instance that is primarily for developer testing. It may not be always available, or there may be several of them.
- Bleed: An environment that is left uncontrolled, either by being continuously deployed from master or by letting otherwise pinned versions of components float up
In some cases work is corralled in routine maintenance windows. This is both to minimize the potential of disruption in high availability environments and to allow co-ordination of work on multiple services and/or infrastructure; and also to issue a “hold off reporting problems” to users. Maintenance windows do not imply fixed downtime. Downtime (complete service unavailability) is extremely rare and we design our processes to avoid it. Routine maintenance work involves transient service unavailability at most and in most cases users are not barred from using the system during that time, though they are given notice to save their work and there is always a small chance of unforseen problems. A co-ordinator is assigned to announce work start and work end and field any questions.
Current fixed maintenance windows (for applicable services/deployments) are:
- All telescope deployments: 1st Wednesday of every month, late afternoon in Chile (approx 2pm PT), confirmed with the telescope software configuration manager.
- Any other deployment subject to maintenance window: Weekly, Thursday afternoons (approx 3pm PT).
Again, these are not scheduled downtimes. In the event that extended service downtime is needed in a production service (extremely rare), work would be scheduled out of normal hours with ample notice and co-ordination with stakeholders.
Here is a chart showing the current settled-upon practice in select areas:
| Service Instance | Bleed | Dev | Int | Prod |
|---|---|---|---|---|
| Science Platform - Science Deployments (IDF, LDF, USDF) | Automatic | Developer-at-will, no heads-up required |
#rsp-team
channel announcement, courtesy 1hr notice |
Release manager has to okay on
#rsp-team
, 24 hour notice minimum |
| Science Platform - Telescope Deployments(summit, base, NTS) | N/A | Developer-at-will, no heads-up required |
#com-square
notice, in maintenance window |
#com-square
notice,
#summit-testing-announcements
notice, in maintenance window |
| EFD | N/A | Developer-at-will, no heads-up required |
#com-square
notice, in maintenance window |
#com-square
notice,
#summit-testing-announcements
notice, in maintenance window |
| Roundtable (LSST-the-docs and other non-data services), SQuaSH | N/A | Developer-at-will, no heads-up required | Developer-at-will, no heads-up required | If service disruption is expected, in maintenance window, notice in relevant service channels (#dm-docs, etc). Otherwise at-will. |
| community.lsst.org | N/A | N/A | N/A | If service disruption is expected, out-of-hours in co-ordination with
#rubinobs-forum-team
. Otherwise in maintenance window. |
5 Container Environments in the Science Platform¶
The above discussion pertains to services, ie codebases where an error could affect a service’s availability. When it comes to containers made available _by_ a service (eg in nublado), we are less risk averse as users, by design, can always fall back on a previously usable container in case of problems. We recognize that the Science Platform is a primary user environment and as such users do not wish to wait a week for some process to take its course in order to get a requested package or feature. We currently (and anticipate continuing to do so) provide containers labeled “experimental” to rapidly service ad-hoc user requests, for example.
How to reconcile this user-first orientation to the issue of scientific reproducibility is a matter for a future technote.